顺序表和链表
顺序表
定义和基础理论
顺序表是在计算机内存中以数组的形式保存的线性表,可见,数组是一种顺序表,但是不能说顺序表是数组;并且顺序表是一种随机存取(只要确定存储线性表的起始位置,线性表中任一数据都可随机存取)的存储结构
一般定义如下,其中ElemType是自定义类型:
#define MAXSIZE 100
typedef struct
{
ElemType *elem;
int length;
}sqList;
初始化完成后,elem指向顺序表的基地址;length则是表示顺序表中当前数据元素的个数
基础操作
初始化
本质就是构建一个空的顺序表
Status InitList(sqList &L)
{
L.elem = new ElemType[MAXSIZE];
if (!L.elem) exit(OVERFLOW);
L.length = 0;
return OK;
}
此处是动态创建线性表的存储区域,这种可以有效的利用系统的资源,当不需要的时候可以销毁并释放资源
取值
根据位置序号i,获取顺序表中第i个数据元素的值;由于顺序结构具有随机存取的特点,可以直接通过数组下标定位得到
Status GetElem(sqList L, int i, Elemtype &e)
{
if (i < 1 || i > L.length) return ERROR;
e = L.elem[i - 1];
return OK;
}
先是判断序号i是否合理,然后直接取出赋值即可;时间复杂度为O(1)
查找
根据指定的元素值e,查找顺序表中第1个与e相等的元素,找到则返回,否则返回0
int LocateElem(sqList L, ElemType e)
{
for (i = 0; i < L.length; i++)
if (L.elem[i] == e) return i + 1;
return 0;
}
进行查找操作的时候,时间消耗主要在数据的比较上,比较次数决定于被查找元素在顺序表中的位置;时间复杂度为O(n)
插入
在表的第i个位置插入一个新的元素e,使长度为n的线性表变成长度为n + 1的线性表;不难看出,在顺序表中的存储结构发生了变化,这使得i后面的元素都需要往后移动一位
Status ListInsert(sqList &L, int i, Elemtype e)
{
if (i < 1 || i > L.length + 1) return ERROR;
if (L.length == MAXSIZE) return ERROR;
for (j = L.length - 1; j >= i - 1; j--)
L.elem[j + 1] = L.elem[j];
L.elem[i - 1] = e;
++L.length;
return OK;
}
插入操作时间消耗主要是在移动元素上,移动元素的个数取决于插入元素的位置;时间复杂度为O(n)
删除
将表的第i个元素删去,将长度为n的顺序表变为长度为n - 1;也就是,将第i + 1到n的元素全部往前移动一个位置
Status ListDelete(sqList &L, int i)
{
if (i < 1 || i > L.length) return ERROR;
for (j = i; j <= L.length -1; j++)
L.elem[j - 1] = L.elem[j];
--L.length;
return OK;
}
跟插入类似,时间消耗主要在移动元素上,个数也取决于删除元素的位置;时间复杂度为O(n)
总结
顺序表可以随机存取表中任一元素,其存储位置可用一个简单、直观的公式表示;但也会有缺点,在做插入删除的时候会移动大量元素,如果元素个数较多,操作会更复杂
链表
定义和基础理论
链表不同于顺序表(数组)它的结构像一条链一样链接成一个线性结构,而链表中每一个结点都存在不同的地址中,链表你可以理解为它存储了指向结点(区域)的地址,能够通过这个指针找到对应结点;链表包括两个域
- 数据域:存储数据元素信息
- 指针域:存储直接后继存储位置
如果每个结点只包含一个指针域,那么即是线性链表或单链表;根据链表结点所含指针个数、指针指向、指针连接方式,可以将链表分为单链表、循环链表、双向链表等
typedef struct LNode
{
ElemType data;//数据域
struct LNode *next;//指针域
}LNode, *LinkList;
LNode和*LinkList本质是一样的,只是为了提高程序的可读性;习惯上使用LinkList定义单链表,强调定义的是单链表的头指针,使用LNode *定义单链表中结点的指针变量;需要强调的是,指针变量和结点变量是两个不同的概念,若定义LinkList p或LNode p,p为指向某结点的指针变量,表示该结点的地址,而p为对应的结点变量,表示该结点的名称
关于链表,一个很重要的知识点就是头结点问题,为了方便处理,一般是选用带头结点的链表,主要是为了首元节点(链表中存储第一个数据元素的结点)和判断非空的处理
链表与顺序表不同的是,链表采用的是顺序存取的存取结构
基础操作
初始化
构造一个空表
Status InitList(LinkList &L)
{
L = new LNode;
L->next = NULL;
return OK;
}
生成新结点作为头结点,用头指针L指向头结点
取值
与顺序表不同,由于链表中逻辑相邻的结点并没有存储在物理相邻的单元中 ,所以在链表中获取结点的值不能向顺序表那样随机访问,只能通过链域逐个结点向下访问
Status GetElem(LinkList L, int i, Elemtype &e)
{
p = L->next;
j = 1;
while(p &&j < i)
{
p = p->next;
++j;
}
if (!p || j > i) return ERROR;
e = p->data;
return OK;
}
由于存取结构不一样,所以会比顺序表在时间复杂度会更高,为O(n)
查找
从链表的首元结点出发,依次将结点值和给定值e比较,返回查找结果
LNode *LocateElem(LinkList L, ElemType e)
{
p = L->next;
while(p && p->data != e)
p = p->next;
return p;
}
执行时间与待查找的值e有关,时间复杂度为O(n)
插入
将值为e的新结点插入到表的第i个结点的位置上
插入步骤大概是,先生成一个结点p,将其数据域Data4置为e,然后将p结点指针域指向Data2的指针域(这里为了方便理解和匹配下图,实际怎么称呼是不合理的),最后将Data1的指针域指向p结点的指针域
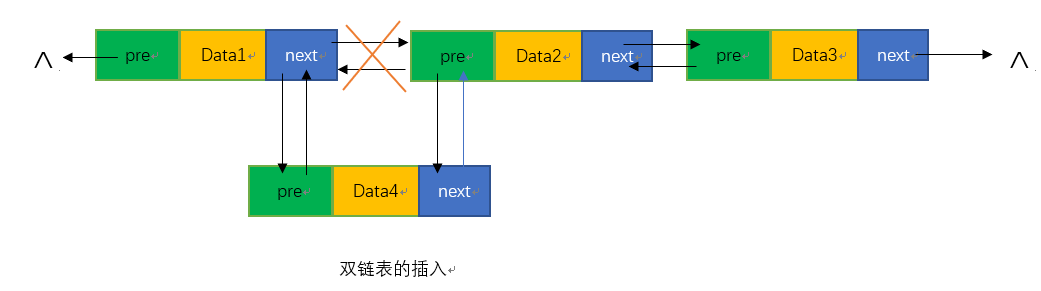
Status ListInsert(LinkList)
{
p = L;
j = 0;
while(p && (j < i - 1))
{
p = p->next;
++j;
}
if (!p || j > i - 1) return ERROR;
s = new LNode;
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}
和顺序表一样,如果表中有n个结点,则插入操作中合法的插入位置有n + 1个,当i= n + 1时,新结点则插在链表尾部;虽然不需要想顺序表的插入那么大量移动元素,但是平均时间复杂度仍然为O(n),这是因为想在i处插入,就必须找到i - 1个结点
删除
删除单链表中指定位置的元素,同插入元素一样,首先应该找到该位置的前驱结点;
大致步骤是,首先是查找第i - 1个结点,找到之后保存一下,以便释放,然后改变指针域,也就是直接跳过即可,最后释放资源
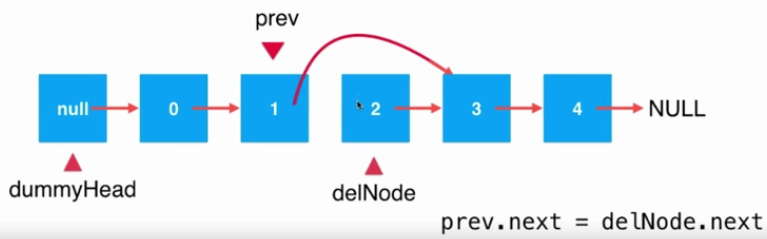
Status ListDelete(LinkList &L, int i)
{
p = L;
j = 0;
while((p->next) && (j < i - 1))
{
p = p->next;
++j;
}
if (!(p->next) || (j > i - 1)) return ERROR;
q = p->next;
p->next = q->next;
delete q;
return OK;
}
和顺序表一样,删除中合法位置有n个;类似插入算法,时间复杂度为O(n)
创建
创建链表按照位置分为前插法和后插法
前插法是通过将新结点逐个插入链表的头部来创建链表,每次申请一个新结点,读入相应的数据元素值,然后将新结点插入到新结点之后
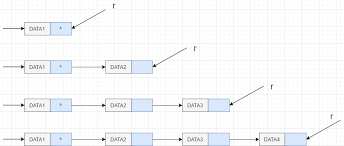
void CreateLiist (LinkList &L, int n)
{
L = new LNode;
L->next = NULL;
for (i = 0; i < n; ++i)
{
p = new LNode;
cin>>p->data;
p->next=L->next;
l->next=p;
}
}
后插法是通过将新结点逐个插入到链表的尾部俩创建链表;与前插法相同的是,每次申请一个新结点,读入相应的数据元素值;不同的是,为了新结点能够插入到表尾,需要增加一个尾指针r指向链表的尾结点
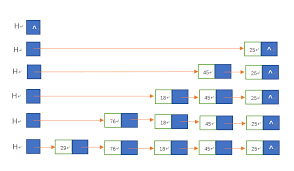
void CreateList_R(LinkList &L, int n)
{
L = new LNode;
L->next = NULL;
r = L;
for (i = 0; i < n; ++i)
{
p = new LNode;
cin>>p->data;
p->next = NULL;
r->next = p;
r = p;
}
}
头插法:
- 插入速度快(不需要遍历旧链表)
- 头结点每次插入都会变化,头结点永远是最新的元素
- 遍历时是按照插入相反的顺序进行
- 由于头结点不断在变化,所以需要额外的维护头结点的引用,否则找不到头结点,链表就废了
尾插法:
- 插入速度慢(需要遍历旧链表到最后一个元素)
- 头结点永远固定不变
- 遍历时是按照插入相同的顺序进行
循环链表
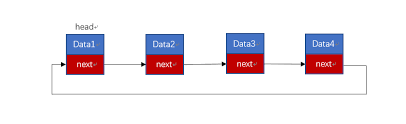
循环链表是一种链式的存储结构,与单链表不同的是,循环链表的最后一个结点的指针是指向该循环链表的第一个结点或者头结点,从而构成一个环形的链
循环链表的运算与单链表的运算基本一致,所不同的有以下几点:
- 在建立一个循环链表时,必须使其最后一个结点的指针指向表头结点,而不是像单链表那样置为NULL。此种情况还使用于在最后一个结点后插入一个新的结点
- 在判断是否到表尾时,是判断该结点指针域的值是否是表头结点,当指针域等于表头指针时,说明已到表尾。而非像单链表那样判断链域值是否为NULL
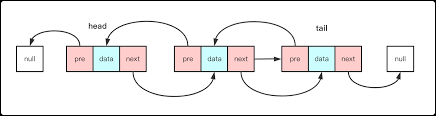
双向链表
双向链表也叫双链表,它的每个数据结点都有两个指针,分别指向前驱结点和后继节点,同时有一个数据域来保存数据
- 链表节点(list_node)带有prev和next两个指针,这意味着,可以从表头到表尾或表尾到表头两个方向遍历或迭代链表
- 链表本身(list)和队列(queue)类似,维护head和tail两个指针,这意味着,在表头或者表尾的插入的复杂度为O(1),而单链表在表尾执行插入操作时,需要从表头遍历到表尾后插入,复杂度为O(n)
顺序表和链表的比较
空间性能
顺序表的存储空间必须预先分配,元素个数扩充受限制,容易造成存储空间浪费或空间溢出,而链表不需要为其预先分配空间,即只要空间允许,链表元素个数可以无限制
除了存储空间,其次就是存储密度(数据元素本身占用存储量/结点结果占用存储量);链表的每个结点除了设置数据域用来存储数据元素外,还要额外设置指针域,用来存储指示元素之后逻辑关系的指针,即链表存储密度小于1,而顺序表存储密度等于1
时间性能
顺序表是由数组实现的,它是一种随机存取结构,指定任意一个位置序号i,都可以在O(1)时间内直接存取该位置上的元素,即取值操作的效率高;而链表是一种顺序存取结构,按位置访问链表中第i个元素时,只能从表头开始依次向后遍历链表,直到找到第i个位置上的元素,时间复杂度为0(n),即取值操作的效率低。基于此,若线性表的主要操作是和元素位置紧密相关的这类取值操作,很少做插入或删除时,宜采用顺序表作为存储结构
对于链表,在确定插入或删除的位置后,插入或删除操作无需移动数据,只需要修改指针,时间复杂度为0(1)。而对于顺序表,进行插入或删除时,平均要移动表中近一半的结点,时间复杂度为0(n)。尤其是当每个结点的信息量较大时,移动结点的时间开销就相当可观。基于此,对于频繁进行插入或删除操作的线性表,宜采用链表作为存储结构